最近打算回顾一些系统领域经典的论文,整理成笔记,希望能从过去的工作中获得一些启发。
概述
Borg 是 Google 内部使用的大规模集群管理系统,跟开源的 Kubernetes 一脉相承,本文发表于 EuroSys 2015 (个人感觉是 Google 特别偏好的会议)。
[Paper][Slides][Youtube Video]
这篇博客主要会聊下 Borg 在论文中描述的系统架构,并尝试分析其中设计精妙之处。
主要内容
基本概念
这里介绍一些 Borg 中常用到的基本概念:
- 用户以 job 的形式提交作业,其中包含了一个或多个 task 执行相同的二进制程序。Job 主要分为两种类型,prod 一般指长期运行的在线服务,对时延敏感,具有高优先级;non-prod 一般指批处理任务,需要花费一定的时间来处理,但对于短期的性能波动不敏感,优先级较低。同时,job 具有一些 constraints,代表了任务对于运行环境的要求或偏好。为了避免硬件虚拟化的成本,绝大部分的 job 都运行在一个 container (not in VM) 中。
- 每个 job 都跑在一个 Borg cell 中,cell 对机器进行统一管理。同一个 cell 里的机器都在一个 cluster 中,存放在一个数据中心里,一个 cluster 包含一个大规模的 cell 和一些小规模(测试或特殊用途)的 cell。
- Borg alloc 表示在一个机器上预留的资源组,资源无论是否被使用都处于分配状态,alloc 可以用于给未来的 task 预留资源,或者在 task 重启的过程中保留资源。alloc set 由多个 alloc 组成,用于预留多台机器上的资源。
- 每个提交的 job 都有 priority,一个代表优先级的数字。在 Borg 中,优先级从大到小分别为:monitoring > production > batch > best effort。值得一提的是,监控组件在系统中的优先级最高。此外,为了限制不同用户使用资源的上限,引入了 quota 的概念,表示不同 priority 的任务最多能使用的资源量,quota 的分配独立在 Borg 之外,进行实际资源用量的规划。
系统架构
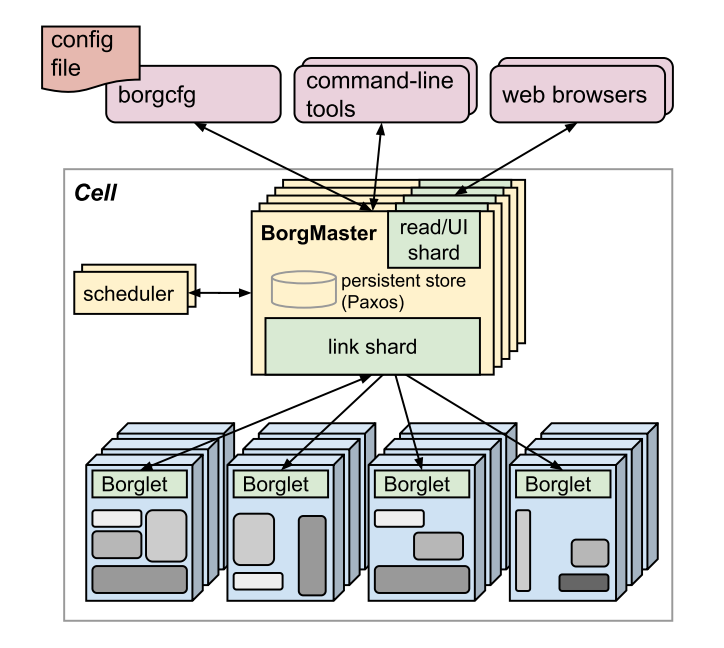
Borg 的系统架构图如图1所示。一个 Borg cell 负责管理一组机器,中心化的控制器 (logically centralized controller) Borgmaster 用于维护整个系统的状态,与运行在每台机器上的代理进程 (agent process) Borglet 进行交互,让用户通过 web UI 的形式 Sigma 来检查任务的状态。Borg 中所有的组件都是由 c++ 编写。
逻辑上 Borgmaster 是一个单独的进程,但会被拷贝五次,将 cell 的状态存储在 Paxos 中。Borgmaster 一个时刻的状态记为 checkpoint,高保真的仿真器 Fauxmaster 可以读取 checkpoint 文件,并与仿真的 Borglet 进行交互,用于复现问题、调试错误。
Borgmaster 除了主进程外,还会运行单独的调度器 scheduler 来调度任务。调度器操作的对象是 task,为了保证公平性,会按优先级从高到低的顺序、以 round-robin 的方式来遍历任务,检查 cell 中是否有足够的可用资源满足任务的需求。这里需要指出,可用资源包括了分配给低优先级任务的资源,这部分资源可以被抢占,然后分配给新的任务。为了减少任务的启动时间 (task startup latency),调度器会倾向于将任务调度到已经拥有相应环境的机器 (data locality)。针对不同类型的 workload,Borg 会相应使用不同的调度器。
每隔一段时间,Borgmaster 会选出一些 Borglet 来获取机器的实时状态,通过无状态的 link shard 来进行通信,link shard 用于聚合 Borglet 采集的完整状态,但只上报其中发生变化的部分。
利用率与隔离性
Increasing utlization by a few percentage points can save millions of dollars.
对于 Google 这种规模的集群来说,每提升一点利用率都能节省大量的成本。因此,Borg 做了不少努力来提升集群的整体利用率。
- 共享 cell 让不同的任务混部在一起,通过运行 non-prod 任务来充分利用未使用的资源,并通过 CPI (cycles per instruction) 指标来检测任务之间可能带来的干扰。
- 构建足够大的 cell 来支持大规模的计算,并减少资源碎片的现象。
- 支持精细化的资源申请量,如按 milli-cores 的粒度来分配 CPU,以及按字节数的粒度来分配内存和磁盘空间。
- 用户会为他们的任务申请过量的资源,导致资源申请量和实际使用量之间存在差异。每隔几秒钟,Borgmaster 会通过 Borglet 采集的精细化的资源用量 usage,来预估任务实际的资源用量 reservation,回收其中已分配但未使用的资源 (resource reclamation)。当 reservation 预估错误时,可能导致整机资源耗尽,这时只会杀死 (kill) 或压制 (throttle) non-prod 类型的任务,从而缓解资源紧缺的问题。
同时,为了确保同一台机器上的任务不会产生干扰,Borg 使用 Linux chroot 作为主要的安全隔离机制。所有的任务都分别跑在一个 Linux cgroup-based 的容器中。
任务使用的资源可以分为两大类,分别是可压缩资源(如 CPU、磁盘 I/O 带宽等)和不可压缩资源(如内存、磁盘空间等)。当机器上的不可压缩资源用尽时,Borglet 会按优先级从小到大的顺序杀死任务;而当可压缩资源用尽时,Borglet 只需要压制某些任务的资源使用,而不用杀死任何任务。Borglet 负责给不同容器分配内存,处理 OOM 异常,以及杀死超出资源限制的任务。为了降低延迟和提高 CPU 利用率,Borglet 也在标准 CFS 调度器的基础上做了改进,动态调整资源的分配。
经验教训
Google 在 Borg 的基础上,总结了过去十年来的经验教训,并将这些观察加入到了 Kubernetes 系统的设计中:
-
类似于 Borg alloc,引入了 pod 来封装一个或多个容器,使这些容器可以统一调度到同一台机器并共享资源。
-
加入了 label 用于管理 Kubernetes 中的调度单元 pod,更具灵活性。
- 每个 pod 和 service 都拥有独立的 IP 地址,无需像 Borg 一样需要管理端口。
- 抽象出 service 类型来支持负载均衡,Kubernetes 可以通过 label 自动地选择相应的 pod 来提供服务。
- 每个 Kubernetes 的组件都支持记录事件,用于查询状态或定位错误。
- 类似于 Borgmaster,API server 是 Kubernetes 分布式系统的核心,负责处理请求和操作底层状态对象。
相关工作
除了 Borg 以外,还有一系列与集群管理相关的工作,如 Apache Mesos、YARN、Tupperware (现在更名为 Twine 了)、Aurora、Alibaba Fuxi、Omega,以及开源版本的 Kubernetes。这些系统之间不同的设计理念值得仔细探索一番。
总结
一些题外话:
- 这篇文章的 author list 虽然只有 6 个人,但参与设计、开发的工程师却不计其数(致谢中有提到),正是这些人推动了工业级系统的构建和发展。
- 论文中写到 Borg 的所有组件都是用
c++写的,然而开源版本的 Kubernetes 却是用go写的(可能是年代的问题?当然go也是 Google 设计的语言)。个人比较好奇的一点是, Google 内部是否也将c++版本的代码迁移到了go上,这两个语言的差异会影响到功能的实现和开发的效率么?
最后,Borg 其实已经是几年前的工作,云计算领域的技术更新迭代非常快,过去的许多经验也不一定适用于当下的 workload,但一些分析问题的方法和角度仍然值得我们去回味,系统的优化和升级是一个永无止境的过程。
Reference
[1] Verma, Abhishek, et al. “Large-scale cluster management at Google with Borg.” Proceedings of the Tenth European Conference on Computer Systems. 2015.